La semaine qui vient de s’écouler a été une semaine « hors du temps », plusieurs développeurs et moi-même avons eut le hasard de nous retrouver en même temps sans projet. La décision a donc été prise de profiter de cette opportunité pour en tirer quelque chose, nom de code : « Zamak experiment week ».
L’objectif ? Trouver un projet à accomplir sur la techno et le sujet de notre choix. En vrac les idées qui ont émergé ont été : du social commerce, un lecteur de musique collaboratif, un bot de générateur de rapports de traduction et un bot d’alertes (vocales ou lumineuses). Silex, Angular JS, Raspberry pi, Twitter & Facebook API et Herokuapp étaient de la partie.
De mon côté, j’ai réussi à enrôler un autre développeur pour donner vie à une idée de l’équipe de traduction française.

Lorsque les traducteurs doivent convertir les chaînes dans la langue de Molière, ils se retrouvent assez fréquemment à devoir traduire des chaînes très similaires car les mainteneurs n’ont pas de vision globale des chaînes utilisées dans leur module. Seuls les traducteurs se rendent compte de ce problème. Le souhait a logiquement été émis de trouver un moyen de remonter ces problèmes aux mainteneurs. La semaine serait donc réussie si nous réussissions à donner vie à ce projet.

Une façon d’y parvenir consiste à le faire tourner régulièrement sur la liste des modules publiés extraite du FTP de d.o (attention chargement très long) pour fournir tous les mois un rapport de traduction au mainteneur de chaque module. Si l’on parse quelques modules deux scénarios s’offrent à nous, le premier (et le meilleur) aucune chaîne ne fait doublon, le mainteneur gagne des points de karma auprès des traducteurs. Le second, des chaînes font doublons, le mainteneur doit voir s’il peut s’améliorer.

La liste des doublons est établie selon plusieurs critères, bien entendu plus la chaîne est longue plus l’analyse est pertinente. Deux méthodes sont employées pour faire l’analyse : la première est la similarité (le nombre de caractères identiques entre deux chaînes) et la seconde est basée sur la prononciation des deux chaînes. Les chaînes de moins de 4 caractères sont en revanche ignorées. Le rapport généré ressemble à cela :

La dernière fonctionnalité (probablement la plus intéressante à date) est que l’on peut publier une issue dans l’issue queue du module de façon automatique, de cette façon ce script tourne sur un serveur et le mainteneur est alerté du résultat de l’analyse de son module directement à la source.
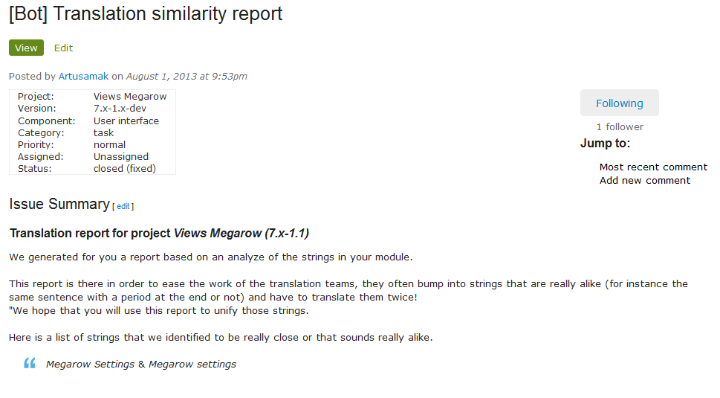
Quelles sont les prochaines étapes de cette expérience ? Tout d’abord les sources de ce projet son publiques, vous êtes les bienvenus pour y contribuer et pour l’améliorer, le README contient quelques suggestions d’améliorations et la liste n’est pas exhaustive. On compte à minima la discussion avec les administrateurs de l’infrastructure de d.o de la fréquence de passage du bot et d’un moyen plus simple de récupérer la liste des projets afin de rendre le projet accessible en ligne. Les mainteneurs devraient également être en mesure de dire si un doublon identifié a du sens ou non afin qu’il ne leur soit plus présenté. On pourra également lier une base de données au projet afin de stocker les rapports pour ne pas les regénérer à l’infini.
Notez que je ne prévois pas spécialement de maintenir le projet de mon côté, si vous souhaitez le voir continuer, impliquez-vous !
Ce projet a en tous cas été l’occasion de mettre en pratique sur un cycle court de l’agilité, MVP, itérations, daily scrums, refactoring ont étés un fil rouge très intéressant. Ça a été pour moi aussi l’occasion de re-goûter à la POO, j’ai expérimenté Silex, Twig et l’API de config, une belle excuse pour doucement basculer vers D8 en douceur.
Je vous recommande vivement d’essayer de mettre en place ce genre d’atelier chez vous, les gens aiment se challenger, ils manquent seulement de prétextes pour le faire.
Et un dernier mot pour dire merci à Maciej qui s’est occupé de la partie algo, parsing et publication du rapport !
Superbe projet, merci pour votre travail.